
Jak narysować i zinterpretować krzywą precision-recall dla klasyfikatora. W artykule pokażę Ci krok po kroku sposób jej wyznaczania teoretycznie oraz praktycznie w scikit-learn. Ponadto, dowiesz się jak ją interpretować, kiedy stosować oraz jak na jej podstawie porównać dwa modele.
We wpisie o miarach klasyfikacji opisałem intuicję i zastosowanie podstawowych miar do oceny klasyfikacji: precision, recall i F1. Jednak w analizie zdolności rozpoznawania klas możemy pójść o krok dalej i wykorzystać do tego celu także wykresy.
Ze wpisu dowiesz się:
- jak powstaje krzywa precision-recall,
- jak ją interpretować i kiedy stosować,
- jak ją wykreślić w scikit-learn,
- jak na jej podstawie ocenić który model jest lepszy.
Wpis jest częścią serii o mierzeniu jakości klasyfikacji, dotychczas powstały:
- Precision, recall i F1 – miary oceny klasyfikatora
- Krzywa Precision-Recall jak ją wykreślić i zinterpretować
- Krzywa ROC (todo)
Obraz wart więcej niż miara F1
Miara F1 jest niewątpliwie użyteczną konstrukcją, jednak lepiej przemawiają do nas dane wizualne w postaci wykresów lub diagramów. Ponadto jedna skumulowana wartość nie oddaje pełnego obrazu możliwości naszego klasyfikatora. W arsenale badacza danych do oceny jego „mocy” mamy dwie magiczne krzywe:
- precision-recall curve
- ROC curve.
Analizując ich wykresy możemy ocenić nasz klasyfikator w szerszym aspekcie. Do wykreślenia obu potrzebujemy „surowych” wartości prawdopodobieństw (pewności) przynależności do klasy. Najczęściej są to znormalizowane wartości z algorytmu uczącego przed „rzutowaniem” na docelowe etykiety. Sposób tworzenia par punktów dla tych krzywych opiera się na zmienianiu wartości progowej, na podstawie której określamy docelowe klasy. Dopiero wtedy liczymy odpowiednie miary jakości (np. precision i recall), które przy zadanym progu (treshold) odkładamy na osiach X i Y.
Ważna uwaga, że taką krzywą wykreślamy dla wybranej klasy. Domyślnie w klasyfikacji binarnej dla klasy pozytywnej, czyli tej zakodowanej jako „1”. Oczywiście nic nie stoi na przeszkodzie, aby takie krzywe kolejno wykreślić dla wszystkich klas np. w problemie wieloklasowym.
Ile progów tyle klasyfikatorów
Przyjrzyjmy się krótkiemu przykładowi. Załóżmy, że mamy wytrenowany model (na chwilę obecną nie obchodzi nas jaki). Jedyne co nas interesuje to to, że w wyniku predykcji naszych danych (data) zwraca tablicę liczb rzeczywistych. Zawiera ona wartość decyzji dla każdego obiektu ze zbioru testowego (możemy je interpretować jako prawdopodobieństwo, ale nie musimy). Dla różnych progów odcięcia otrzymujemy inne wartości docelowych klas. Spójrzmy na mini przykład:
import numpy as np from sklearn import metrics y_true = np.array([0, 0, 0, 0, 0, 1, 1, 1]) # y_score are computed by our classification algorithm # y_score = ClassificationAlgorithm.predict(data) y_score = np.array([0.1, 0.4, 0.35, 0.7, 0.2, 0.3, 0.6, 0.8]) # tresholding, above 0.4 y_pred = (y_score>=0.4).astype(int) # y_pred=[0 1 0 1 0 0 1 1] # tresholding, above 0.6 y_pred = (y_score>=0.6).astype(int) # y_pred=[0 0 0 1 0 0 1 1]
Gdy zastosujemy próg na poziomie 0.4 i wszystko równe lub powyżej tej wartości przypiszemy do klasy 1, a resztę do klasy 0 to otrzymamy klasyfikację: y_pred=[0 1 0 1 0 0 1 1].
Możemy wybrać sobie inną wartość progu np. 0.6 i wtedy rozkład przewidzianych etykiet będzie inny: y_pred=[0 0 0 1 0 0 1 1].
Który próg jest lepszy? Możemy odpowiedzieć na to pytanie licząc różne miary np. precision i recall. Zgadzacie się, że w obu przypadkach będą one inne.
Przykład ten pokazuje, że możemy pójść o krok dalej w ocenie modelu. Nie warto oceniać samego jednego sposobu etykietowania danych (poprzez ustalone progowanie) tylko „zdolność” jaką ma nasz klasyfikator do rozróżniania klas na wielu poziomach progowania. Dobry klasyfikator będzie dawał dobre wyniki przy różnych progach. Oczywiście istnieje ten najlepszy próg. Wykreślona krzywa pokaże ogólną charakterystykę, dzięki której będziemy mogli wybrać lepszy model.
Jak narysować krzywą precision-recall?
Krzywa precision-recall pokazuje zależność pomiędzy miarami precision i recall dla różnych wartości odcięcia klasyfikatora, wykreślamy ją dla wybranej klasy. Pokazuje ona nam ogólną zdolność klasyfikatora do rozpoznawania. Domyślnie w większości bibliotek rysowana jest dla klasy pozytywnej (+1) . Na osi X odkładamy policzone wartości recall a na osi Y precision dla wybranych progów.
Kroki wyznaczania krzywej precision-recal:
- wybieramy wartości progów odcięć klasyfikatora (tresholds) na podstawie wartości z tablicy y_score. Wybiera się takie, które skutkują zmianą etykietowania przynajmniej jednego egzemplarza (zmieni to precision i recall) . W naszym przypadku tablica progów będzie wyglądać następująco: [0.3 , 0.35, 0.4 , 0.6 , 0.7 , 0.8 ]. Przy każdym z tych progów zmienia się etykietowanie naszych elementów.
- dokonujemy etykietowania elementów z y_score dla wybranego progu. Następnie dla takiego etykietowania liczymy precision i recall. W ten sposób mamy pierwszą parę punktów (recall, precision), którą możemy odłożyć na wykresie.
- postępujemy tak jak w punkcie 2 dla kolejnych progów i otrzymanych w ten sposób etykietowań. Odkładamy otrzymaną parę wartości (recall, precision) na wykresie.
Zauważcie, że uzyskany wykres nie jest funkcją, tzn. często dla jakiejś wartości recall otrzymamy kilka przyporządkowań precision. Nie zakładajcie także, że krzywa ta będzie powstawała „od lewej do prawej”. A nawet powstaje od „prawej do lewej”, gdyż dla klasy pozytywnej przy zwiększanym progu recall będzie zmieniał się od 1 do 0. Najlepiej podejść do tego, że dla każdego etykietowania dostajemy parę punktów, które umieszczamy w dwu wymiarowej przestrzeni. Na koniec możemy te punkty połączyć linią.
Prescision-recall curve w scikit-learn
Do wygenerowania omawianej krzywej posłużymy się biblioteką scikit-learn. Rozbudowany przykład znajduje się na moim Githubie w pliku precision_recall_curve.py
"""Example of computing precision recall curve
"""
#%%
import matplotlib.pyplot as plt
import numpy as np
import sklearn.metrics as skm
y_true = np.array([0, 0, 0, 0, 0, 1, 1, 1])
y_score = np.array([0.1, 0.4, 0.35, 0.7, 0.2, 0.3, 0.6, 0.8])
#%% compute precision recall for all classes
precision0, recall0, tresholds0 = skm.precision_recall_curve(y_true, 1-y_score, pos_label=0)
precision1, recall1, tresholds1 = skm.precision_recall_curve(y_true, y_score, pos_label=1)
#%% plot curve
plt.plot(recall0, precision0, 'ro')
plt.plot(recall0, precision0, 'r', label='class 0')
plt.plot(recall1, precision1, 'bo')
plt.plot(recall1, precision1, 'b', label='class 1')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.ylim([0.0, 1.05])
plt.xlim([0.0, 1.0])
plt.title('2-class Precision-Recall curve')
plt.legend()
plt.show() W pierwszych wierszach deklarujemy dane: y_true reprezentuje rzeczywiste etykiety, y_score natomiast wartości liczbowe decyzji klasyfikatora, jeszcze przed rzutowaniem na klasy.
Następnie korzystając z funkcji z sklearn.metrics.precision_recall_curve kolejno dla klasy 0 i 1 wyznaczamy wartości precision, recall i tresholds. W przypadku liczenia miar dla klasy 0 poszedłem trochę na skróty i zastosowałem mały hak. Ustalając argument funkcji pos_label=0 dodatkowo trzeba odwrócić wartości z tablicy y_score, bo były liczone z założeniem, że klasa pozytywna kodowana jest jako 1, a nie 0.
Na koniec z wykorzytaniem matplotlib oznaczamy punkty na wykresie plt.plot(recall0, precision0, 'ro’) a później je łączymy linią ciągłą plt.plot(recall0, precision0, 'r’, label=’class 0′)
W wyniku uruchomienia kodu naszym oczom powinien ukazać się następujący wykres.

Interpretacja krzywej precision-recall
Przypadek losowy
Zacznijmy od przypadku najgorszego. Niech nasz klasyfikator działa losowo zgodnie z rozkładem elementów w datasecie. Gdy stosunek klas pozytywnej do negatywnej wynosi 1:1 to wykres będzie przebiegał mniej więcej na wysokości 0.5 (50% szans trafienia poprawnej klasy).
Poniżej 3 przykłady takich krzywych dla różnej ilości elementów w zbiorze: 10, 100, 1000. Zauważcie, krzywa zbiega do oczekiwanej wartości 0.5

Krzywa precision recall dla losowego klasyfikatora 10 obiektów. EN precision recall curve – random classifier 10 samples Krzywa precision recall dla losowego klasyfikatora 100 obiektów. EN precision recall curve – random classifier 100 samples Krzywa precision recall dla losowego klasyfikatora 1000 obiektów. EN precision recall curve – random classifier 1000 samples



Natomiast gdy zmienimy rozkład klas w stosunku 1:2 (pozytywna:negatywna) to dla losowego przyporządkowania krzywa będzie zbiegała do wartości 0.33.



Przypadek idealny
Przejdźmy teraz do kolejnego skrajnego przypadku, czyli idealnego klasyfikatora. Zanim przeczytasz dalej, to proszę zastanów się jak może wyglądać taka krzywa w przypadku idealnym. Na jakim poziomie będzie wykres, gdzie się zaczyna i gdzie kończy?

Otóż pewnie dobrze rozkminiłeś. Skoro klasyfikator jest idealny to precision dla różnych wartości recall powinno wynosić 1. Zwiększając kolejno próg będziemy otrzymywać poprawne rozpoznanie, jedyne co będzie się zmieniać(zmniejszać!) to recall.

Poniżej kod generujący powyższe wykresy, a szczegółowy kod z komentarzami znajduje się na moim GitHubie w projekcie ksopyla/scikit-learn-turorial w pliku /metrics/precision_recall_curve_edge_case.py.
"""Example of computing precision recall curve for random and ideal
classifier.
"""
# %%
import matplotlib.pyplot as plt
import numpy as np
import sklearn.metrics as skm
# %% random classifier balanced data
# set random seed for reproducibility
np.random.seed(5)
N = 10 # change this number try: 10, 100, 1000
pos_class_prob=1.0/3 # try 1.0/2 1.0/3 2.0/3
# generate N random samples [0,1], positive examples are sampled with probability 'pos_class_prob'
y_true = np.random.choice(np.array([0, 1]),N, p=[1-pos_class_prob,pos_class_prob])
y_score=np.random.rand(N)
precision, recall, tresholds=skm.precision_recall_curve(y_true, y_score)
# % plot curve
plt.plot(recall, precision, 'bo')
plt.plot(recall, precision, 'b', label='class 1')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.ylim([0.0, 1.05])
plt.xlim([0.0, 1.0])
plt.title(f'Precision-Recall curve for random classifier, {N} samples')
plt.grid(True)
plt.show()
# %%
# %% ideal classifier
# set random seed for reproducibility
np.random.seed(5)
N=50
# in order to generate ideal classifier, we first generate scores and then labels
y_score=np.random.rand(N)
y_true = (y_score>=0.5).astype(int)
precision, recall, tresholds=skm.precision_recall_curve(y_true, y_score)
#%% plot curve
plt.plot(recall, precision, 'bo')
plt.plot(recall, precision, 'b', label='class 1')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.ylim([0.0, 1.05])
plt.xlim([0.0, 1.0])
plt.title(f'Precision-Recall curve for ideal classifier, {N} samples')
plt.grid(True)
plt.show()Porównujemy dwa modele do siebie
Porównując krzywe dla dwóch wytrenowanych modeli łatwo możemy ocenić który jest lepszy w sytuacji, gdzie jedna krzywa dominuje drugą.

A co w sytuacji, w której nie ma krzywej dominującej tylko przecinają się, tak jak poniżej?
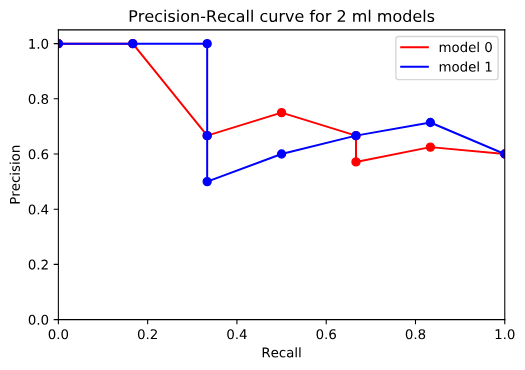
W takiej sytuacji zwracamy uwagę na to, dla której krzywej powierzchnia pod wykresem jest większa. Oczywiście lepszy model będzie miał większą powierzchnię. No niby proste, ale na wykresie nie jest łatwo to odczytać. Mogą pomóc nam w tym dwie dodatkowe miary pierwsza to sklearn.metrics.average_precision_score a druga to sklearn.metrics.auc. Obie w trochę inny sposób (poczytajcie sobie dokumentację) obliczają to pole. Stosując je w naszym przypadku otrzymamy:
Model 0 average_precision=0.7180555555555556 area under curve=0.7434523809523809
Model 1 average_precision=0.7634920634920634 area under curve=0.7551587301587301
Skrócony kod przykładu porównującego modele znajduje się poniżej a całość na GitHubie w projekcie ksopyla/scikit-learn-turorial w pliku /metrics/precision_recall_curve_model_comparision.py
"""Example of computing precision recall curve
"""
# %%
import matplotlib.pyplot as plt
import numpy as np
import sklearn.metrics as skm
y_true = np.array([0, 0, 0, 0, 1, 1, 1, 1, 1, 1])
# looking only at curves it is not so obvious, which one is better
# output from model0
y_score0 = np.array([0.7, 0.45, 0.3, 0.35, 0.45, 0.7, 0.3, 0.33, 0.55, 0.8])
# output from model1
y_score1 = np.array([0.6, 0.3, 0.3, 0.55, 0.65, 0.4, 0.5, 0.33, 0.75, 0.3])
#%%
# first model
precision0, recall0, tresholds0 = skm.precision_recall_curve(y_true, y_score0)
# second model
precision1, recall1, tresholds1 = skm.precision_recall_curve(y_true, y_score1)
avg_prec0 = skm.average_precision_score(y_true, y_score0)
auc0 = skm.auc(recall0,precision0)
print(f"Model 0 average_precision={avg_prec0} area under curve={auc0}")
avg_prec1 = skm.average_precision_score(y_true, y_score1)
auc1 = skm.auc(recall1,precision1)
print(f"Model 1 average_precision={avg_prec1} area under curve={auc1}")
#%% plot curve
plt.plot(recall0, precision0, 'ro')
plt.plot(recall0, precision0, 'r', label='model 0')
plt.plot(recall1, precision1, 'bo')
plt.plot(recall1, precision1, 'b', label='model 1')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.ylim([0.0, 1.05])
plt.xlim([0.0, 1.0])
plt.title('Precision-Recall curve for 2 ml models')
plt.legend()
plt.show()
Podsumowanie
We wpisie poruszyłem temat oceny jakości klasyfikatora przy pomocy krzywych precision-recall. Omówiliśmy jak taką krzywą wykreślić w scikit-learn, jak ją interpretować i wykorzystać do porównywania modeli uczenia maszynowego.
Wszystkie przykłady znajdują się na githubie w repozytorium https://github.com/ksopyla/scikit-learn-tutorial.
Sklonuj je lub sforkuj do siebie oraz będę wdzięczny jeżeli oznaczysz gwiazdką.
Materiały dodatkowe
- https://classeval.wordpress.com/introduction/introduction-to-the-precision-recall-plot/
- https://machinelearningmastery.com/roc-curves-and-precision-recall-curves-for-classification-in-python/ – wpis wyjaśniający czym są krzywe ROC oraz precision/recall
- https://scikit-learn.org/stable/auto_examples/model_selection/plot_precision_recall.html – dokumentacja scikit-learn na temat precision recall
- https://acutecaretesting.org/en/articles/precision-recall-curves-what-are-they-and-how-are-they-used
- http://signalsurgeon.com/how-and-when-to-use-roc-curves-and-precision-recall-curves-for-classification-in-python/
Jeżeli uważasz ten wpis za wartościowy to Zasubskrybuj bloga. Dostaniesz informacje o nowych artykułach.
Photo by Nick Fewings on Unsplash
Szanowny Panie Krzysztofie,
W przypadku krzywej ROC-a, wybierając dowolny punkt na niej, możemy z osi Y (Sensitivity) odczytać „zysk”, tzn. ile % model jest w stanie prawidłowo zaklasyfikować 1 jako 1, natomiast z osi X (1 – Specificity) możemy odczytać stratę, tzn. ile % model błędnie klasyfikuje 0 jako 1.
Jak by Pan zinterpretował pojedynczy punkt na krzywej Precision-Recall?
Pojedynczy punkt na krzywej precision-recall odpowiada właśnie wartościom precision i recall przy wybranej wartości progu (treshold) klasyfikacji.
Czyli na ile wśród oznaczonych jako „1” jest rzeczywiście „1” oraz ile z tych prawidłowych „1” zostało rozpoznanych.
PS. Bardzo mi miło za zwrot „Szanowny Panie Krzysztofie”, ale nie przepadam za tak formalną formą.